A Collaborative Approach to Topic Modelling and Social Network Analysis on the Letters of John Stevens Henslow
Funded by Cambridge Digital Humanities as part of their Project Incubation Awards, Tracing Ideas Across Networks was conceived with the aim of using the transcribed letters of John Stevens Henslow as the basis for experimenting with different Python tools, gaining insights into both the dataset and the application of digital methods. Our focus was mainly on experimenting with different approaches to topic modelling, using the results to perform social network analysis on the identified topics. A fundamental aim of the project was that it would involve a collaborative approach, working alongside a non-technical academic researcher and making any outputs available to them in an accessible format. For this purpose, the expertise of Professor John Parker, the head of the Henslow Correspondence Project, was drawn upon in analysing results and deciding on the direction of the work as it unfolded.
Having extracted the letter texts from their files, we performed some data cleaning on the texts to standardise them, also removing stop words. We then began our topic modelling process by applying two established techniques to our corpus, Term Frequency Inverse Document Frequency (TFIDF) and Latent Dirichlet Allocation (LDA). Both of these methods were effective in attaching recognisable topics to different documents, with TFIDF allocating a single topic to each document and LDA dividing each document into a set of topics. Topics were identifiable by the top keywords found together within them, with some topics having a greater degree of cohesion than others. For instance, in both cases a clear topic emerged around the theme of elections, voting and Palmerston, reflecting Henslow’s involvement in the campaign for Palmerston’s election to the Cambridge University seat in 1826. Having said this, the models were not greatly successful in telling us anything we did not already know about the corpus.
BERTopic provides a much newer approach to the problem of topic modelling, with a transformers-based system, specifically the Sentence Transformers model. It works on a sentence-by-sentence basis, allowing a greater degree of granularity in identifying topics across the corpus. The initial results of processing the Henslow corpus through the BERTopic algorithm far exceeded our expectations in terms of the accuracy and detail of the topics found. Specific areas of interest to Henslow were clearly identifiable within the topic outputs, including entomology and museums. The built-in visualisation methods provided as part of the BERTopic library also enabled us to view the topic outputs in terms of their appearance over time and see how the themes of the letters shifted.
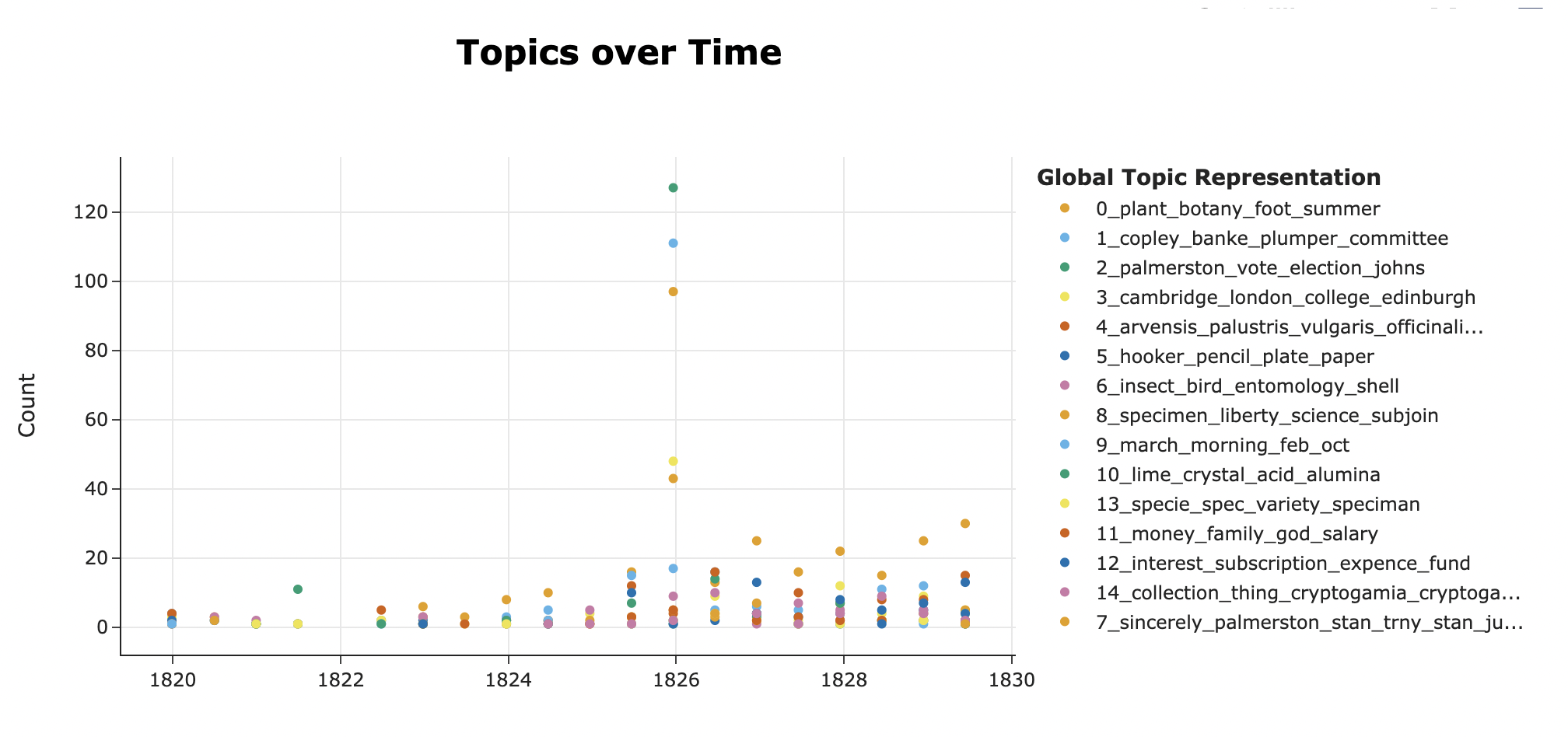
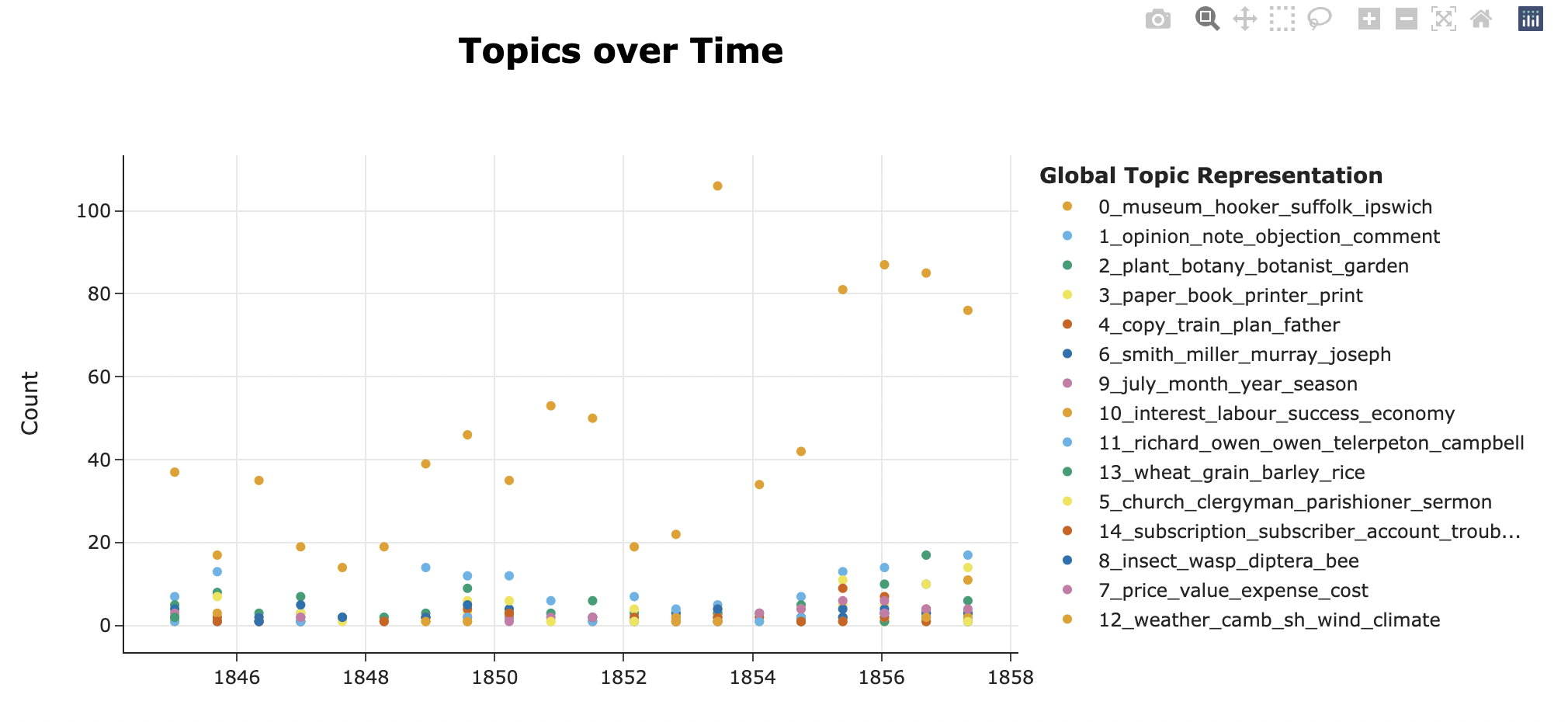
The initial results were then discussed with Professor Parker and several ideas for changes to the inputs and outputs were established. The input data was restricted to more meaningful words by augmenting the stop words and limiting the inclusion of parts-of-speech to nouns and pronouns. This had the immediate effect of increasing the specificity of the topics generated to include more subjects related to Henslow, such as fossils and geology. Outputs were divided according to different parameters, isolating letters to and from Henslow, and enabling the creation of temporal windows, so that the topics from different periods could be seen in isolation. Additionally, a visualisation of the number of letters per year was created, so that spikes in the appearance of topics could be viewed in the context of the number of letters in that year within the corpus.
Having analysed the outputs, the visualisation for the creation of temporal windows was found to be of particular value from a research perspective, enabling the comparison of topics generated in relation to different periods in Henslow’s life. We created two visualisations, one for the 1820s and another for 1845 to 1857, revealing a number of interesting patterns. The later period saw large numbers for topics relating to agriculture and museums, reflecting Henslow’s position as Rector of the parish of Hitcham in rural Suffolk and his involvement in the foundation of the Ipswich Museum. On the other hand, the topic relating to religion had relatively small numbers, reflecting the largely practical, secular content of Henslow’s correspondence at this time, in spite of his position within the Church. The 1820s saw an expected spike in numbers for topics relating to Palmerston around the time of the election campaign and much higher numbers relating to botany than the later period, particularly towards the end of the decade. Taken together, these observations confirmed that the model was providing us with cogent topics that reflected our knowledge of the dataset and also a number of new insights.
BERTopic visualisations
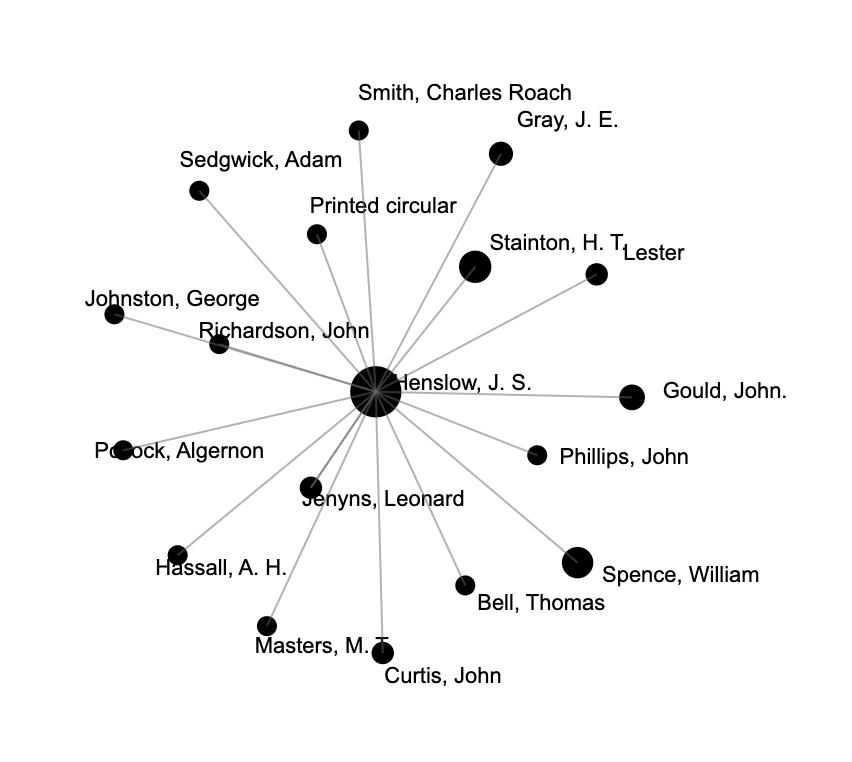
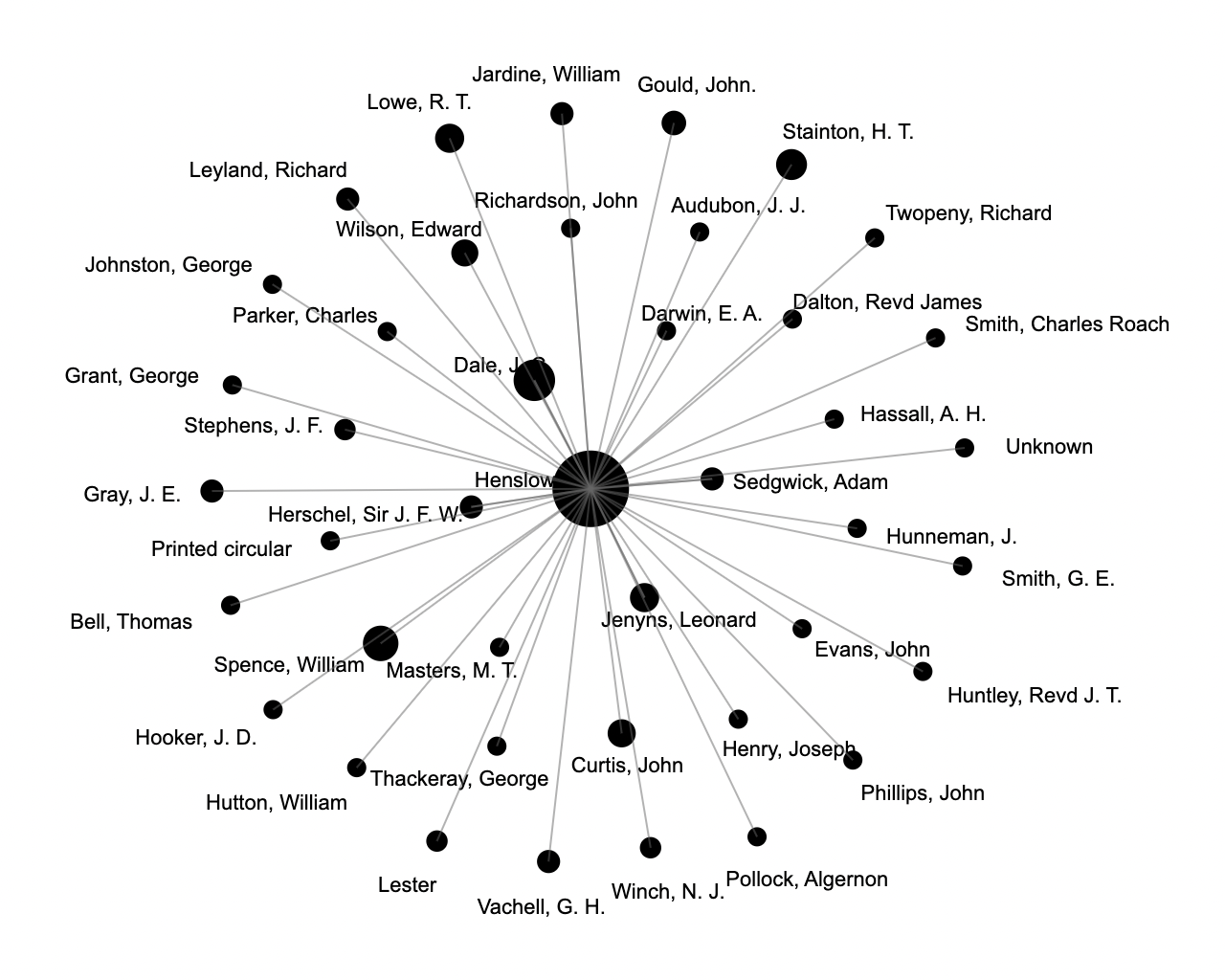
Finally, the BERTopic outputs were used to create social network visualisations with Palladio, an online tool developed at Stanford University. This involved a process of extracting the letter date and correspondents for each instance of a sentence being attached to a topic. The topics and sentence metadata were then exported to Palladio so that a temporal network graph could be generated. Once the Palladio visualisation was ready, the timespan feature was used to generate a time-specific graph for each topic. In our examples, the network around the topic of entomology is viewed for the whole corpus and for the 1850s. This feature enabled us to quickly see the individuals associated with topics and the nature of the social network around topics over time, with such insights providing a springboard for further research into the correspondents associated with topics at certain periods.
Palladio visualisations
Overall, the project was highly illuminating, both in terms of exploring a collaborative process in relation to technical tools and developing a familiarity with those tools in relation to a historic corpus. The accuracy and detail of BERTopic was a revelation and its capacity to draw out unexpected topics definitely allowed us to view the dataset from a new perspective, particularly when used alongside Palladio’s network analysis tool. While the topics generated were not perfect, they had a level of detail and accuracy that provided us with new insights into the corpus and acted as the impetus for further research. The model developed for this project is definitely transferable to other collections of historical text and it would be particularly interesting to see its performance in relation to a larger corpus in the future, particularly on datasets such as Epsilon which might show the transfer of ideas across a network rather than centred on a single correspondent.